项目介绍
目前正在做一个人脸识别的项目,android端RTSP推流至流媒体服务器,服务器转发至后端对视频流进行人脸识别。现在此总结一下。
整体流程
MediaCodec用来进行音视频编码
AudioRecord用来录音得到PCM音频数据
MediaMuxer用来将编码好的音视频数据写入文件
Camera用来采集摄像头的数据
基本介绍
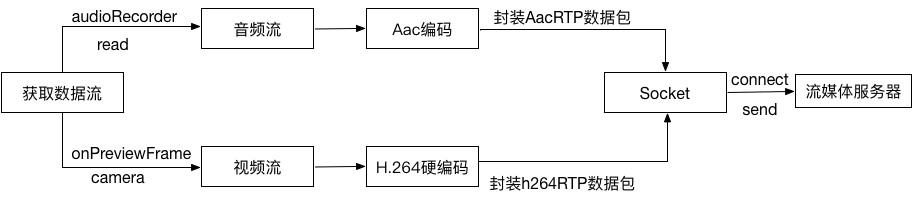
首先通过手机硬件获取音视频流,初始化camera并在onPreviewFrame回调中接受NV21数据,初始化audioRecorder开始录音,初始化自定义的音视频的编码器和音视频混合器mediaMuxer。
视频流在onPreviewFrame回调中对视频流进行H.264编码,并封装成若干个rtp数据包,然后通过socket进行udp或tcp传输至服务器。
音频流使用线程循环获取PCM数据,并使用音频编码器进行AAC编码,封装成若干个rtp数据包,然后通过socket进行udp或tcp传输至服务器。
音视频同步通过写入pts实现。编码时MediaCodec.queueInputBuffer方法中的presentationTimeUs参数便相当于pts。
以下为参数定义。
presentationTimeUs:这个buffer提交呈现的时间戳(微秒),它通常是指这个buffer应该提交或渲染的media time。当使用output surface时,将作为timestamp传递给frame(转换为纳秒后)。
若需要存储至本地,则需要用到mediaMuxer混合音视频。
编码
编码分为软编码和硬编码。
不是所有的设备都支持硬编码。硬编码是指将可变变量用一个固定值来代替的方法。用这种方法编译后,如果以后需要更改此变量就非常困难了。软编码可以在运行时修改,而硬编码是不能够改变的。例如美拍视频则是用的软编码。实时推流一般不会去修改,所以采用硬编码。
软编码使用CPU编码,硬编码采用非CPU,比如GPU,专用芯片等。故软编码的CPU负载重,但低码率下质量要比硬编码好一些。
Android中的H264硬编码主要是通过自身提供的API,调用底层的硬件模块实现编码,不使用CPU。
数据封装
根据RTP协议封包组包,然后传输RTP包至服务器。
推流
推流地址为流媒体服务器的地址,可用EasyDarwin,直接npm run dev即可,连接成功后,可使用vlc播放器播放。目前局域网的延迟为2s左右(人工测算)。
人脸识别
另起一个后台项目,使用javaCV(封装的一个openCV to java interface的库)识别,直接调用方法获取播放地址的每一帧(Frame),根据Frame对象进行人脸识别,切割,保存。识别完成后对每一张人脸进行比对,若有目标人脸,则通过推送的方式将目标人脸的URL和其他信息发给终端。JavaCV也可在android上集成使用。经测试,400+k的图片,包含五张人脸,在1G内存的手机上识别速度大约为2.5s左右。效率不理想。
人脸比对
目前处于讨论阶段